|
I am currently working as a Staff Algorithm Engineer at Alibaba Group, leading the TaoAvatar Team in the Taobao3D Department. Prior to 2017, I worked for several years as a Video Analytic Researcher at Trakomatic Pte. Ltd. in Singapore. I have also served as an Executive Committee Member of the CCF Technical Committee on CAD/CG. I received the B.E. degree in computer science from Shanghai Jiao Tong University in 2012 under the supervision of Prof. Fan Wu and the M.E. degree in computer science from National University of Singapore in 2014. |

|
|
I'm interested in Computer Vision, in particular, Human Reconstruction, Animatable Avatar, Human-Computer Interaction, etc. Below are some highlighted publications. |
|
|
Jianchuan Chen, Jingchuan Hu, Gaige Wang, Zhonghua Jiang, Tiansong Zhou, Zhiwen Chen, Chengfei Lv CVPR 2025 Highlight paper / project page / github We introduce TaoAvatar, which generates photorealistic, topology-consistent 3D full-body avatars from multi-view sequences. It provides high-quality, real-time rendering with low storage requirements, compatible across various mobile and AR devices like the Apple Vision Pro. |
|
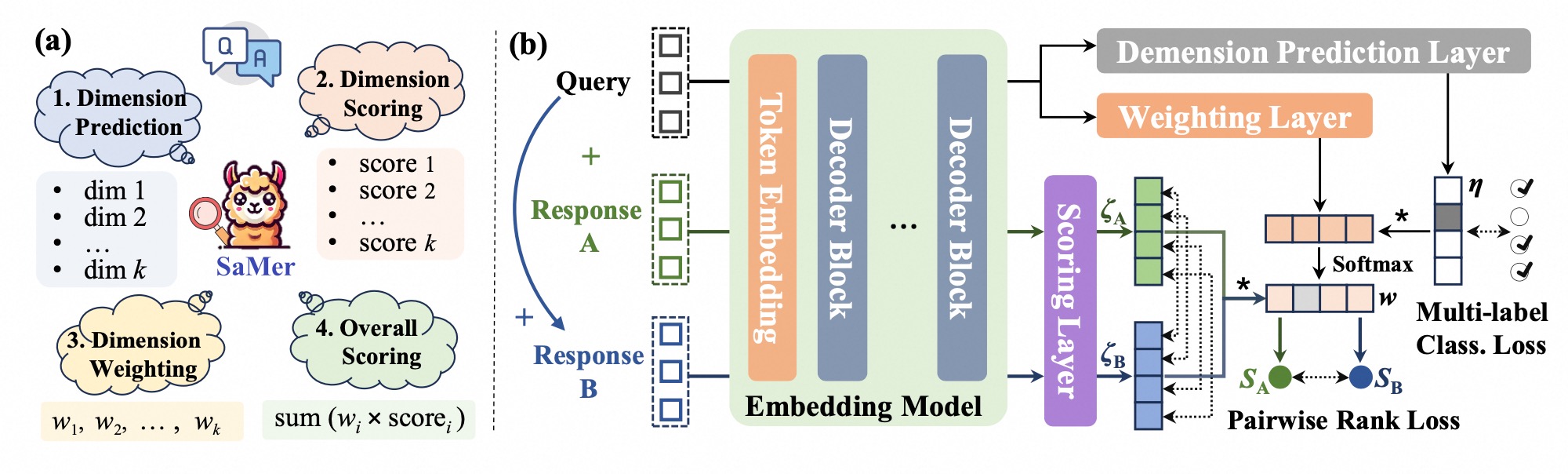
Kehua Feng, Keyan Ding, Jing Yu, Yiwen Qu, Zhiwen Chen, Chengfei Lv, Gang Yu, Qiang Zhang, Huajun Chen ICLR 2025 paper / project page We introduce SaMer, a fine-grained, scenario-adaptive evaluator that dynamically adjusts evaluation dimensions based on query context. |

|
Hongyun Yu, Zhan Qu, Qihang Yu, Jianchuan Chen, Zhonghua Jiang, Zhiwen Chen, Shengyu Zhang, Jimin Xu, Fei Wu, Chengfei Lv, Gang Yu ACM MM 2024 paper / project page We present GaussianTalker, a novel method for audio-driven talking head synthesis based on 3D Gaussian Splatting. It outperforms existing state-of-the-art methods in talking head synthesis, delivering precise lip synchronization and exceptional visual quality. It also achieves rendering speeds of 130 FPS on NVIDIA RTX4090 GPU. |

|
Miao Xu, Xiangyu Zhu, Yueying Kao, Zhiwen Chen, Jiangjing Lyu, Zhen Lei TMM 2024 paper We present a novel framework for 6DoF face pose estimation, where 2D features extracted from images and 3D features representing 3D shape interact with each other in a transformer architecture to learn the 2D-3D correspondence. |

|
Xiangyu Zhu, Tingting Liao, Xiaomei Zhang, Jiangjing Lyu, Zhiwen Chen, Yunfeng Wang, Kan Guo, Qiong Cao, Stan Z. Li, Zhen Lei TBIOM 2023 paper / code We present 3D Avatar Reconstruction in the wild (ARwild), which first reconstructs the implicit skinning fields in a multi-level manner. |

|
Zixuan Huang, Yunfeng Wang, Zhiwen Chen, Xin Gao, Ruili Feng, Xiaobo Li CVPR 2022 Workshop paper We proposed an attention-based model called Context Attention Network (CANet), which integrates the context extraction module in a UNet architecture, can effectively improve the network’s ability to extract the skeleton pixels. We were evaluated 1st place on CVPR DLGC Workshop and Challenge. |

|
Chenxi Wang, Yunfeng Wang, Zixuan Huang, Zhiwen Chen ICCV 2021 Workshop paper We established a simple but effective baseline for single human motion forecasting without visual and social information. We were evaluated 1st place on ICCV SoMoF Workshop and Challenge. |
|
These include workshops, challenges and awards. |
|
Zhengyu Diao, Zhiwen Chen, Yujie Sun, Zhuoqiang Cai CVPR 2025 Challenge 1st place winner of Dynamic Novel View Synthesis Track workshop / challenge |

|
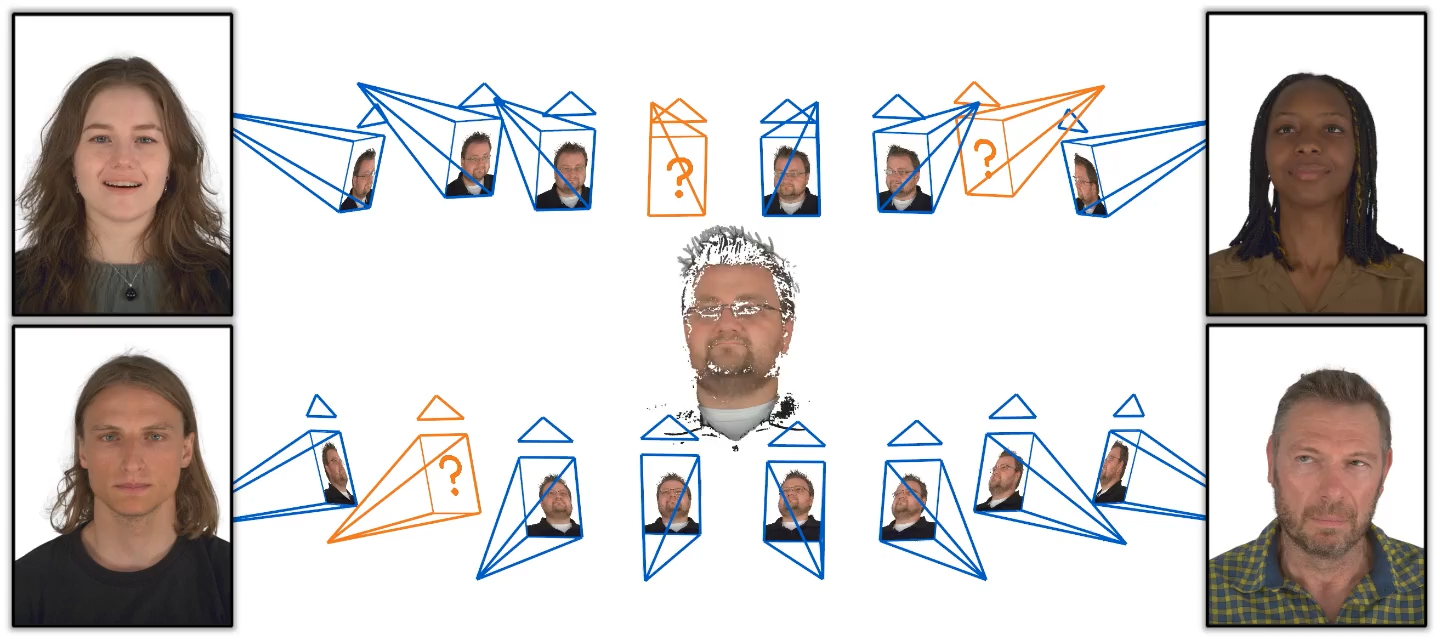
Zhiwen Chen (Challenge Main Organizer) ECCV 2022 Workshop and Challenge challenge We contribute a large-scale dataset, MVP-Human (Multi-View and Multi-Pose 3D Human), which contains 250 subjects. Each subject has 15 type of different poses. Each pose contains 8-view RGB images. |

|
Zixuan Huang, Yunfeng Wang, Zhiwen Chen CVPR 2022 Challenge 1st place winner of Pixel SkelNetOn Track workshop / challenge |

|
Chenxi Wang, Yunfeng Wang, Zixuan Huang, Zhiwen Chen ICCV 2021 Challenge 1st place winner of PoseTrack and 3DPW datasets workshop / challenge |
|
Template copied from Jon Barron and Matiur Rahman Minar. |